
Datenverwaltung
(Webinterface und Datenbank
eines biologischen Forschungsverbundes)
(Stand: Juli 2017)
Hintergrund
Immer mehr biologische und medizinische Experimente generieren große Datenmengen. Diese werden im Hinblick auf die jeweilige Fragestellung analysiert (Beispiel für eine solche Analyse durch BioControl Jena: Omics-Analyse). Nach Abschluss des Experiments und der Analyse muss sichergestellt sein, dass die Daten selbst sowie alle relevanten Metadaten auch weiterhin verfügbar bleiben. In großen Forschungsverbünden sollen außerdem zumindest die Metadaten von allen Mitgliedern zentral an einer Stelle gespeichert und dadurch rechtegesteuert für alle zugänglich sein. Die Erstellung einer Datenbank (Back-end) und eines Webinterface (Front-end) für den Zugriff darauf wird im Folgenden beispielhaft dargestellt. Diese web-basierte Lösung ist im aktiven Einsatz durch einen biologischen Forschungsverbund (Zwischenstand: Juli 2017).
Back-end
Datenerfassung
Microsoft Excel® ist ein weit verbreitetes Werkzeug für die Datenerfassung und kann mittels VBA auch an unterschiedliche Fragestellungen angepasst werden. Daher wurden für die Erfassung der Metadaten aus den RNA-seq-, Microarray- und LC-MS/MS-Experimenten Excel®-Templates entworfen. Diese werden von den Experimentatoren in Zusammenarbeit mit den an der Datenanalyse beteiligten Bioinformatikern ausgefüllt und anschließend mithilfe eines Parsers in die Datenbank übersetzt.
Das erste Blatt jeder Datei dient der Aufnahme allgemeiner, experimentbezogener Daten wie z. B. Experimenttitel und -beschreibung, experimentelle Parameter oder beteiligte Personen:
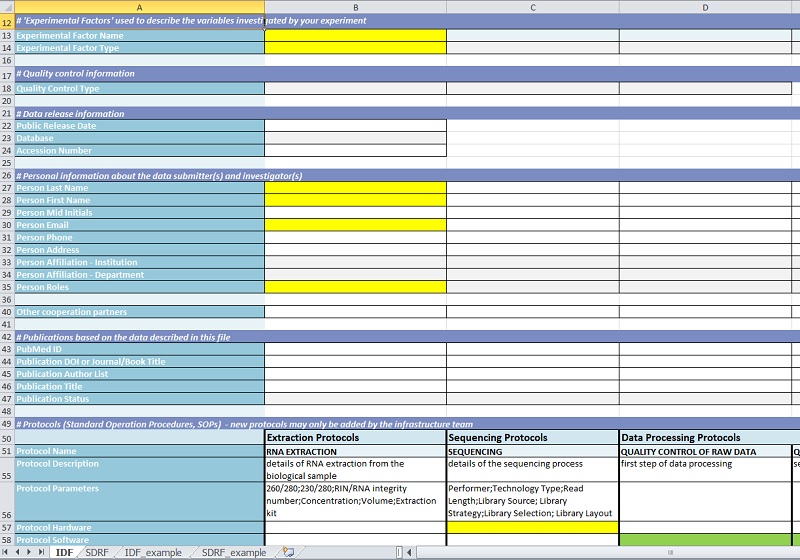
Im zweiten Blatt werden dann Informationen zu den einzelnen biologischen Proben gesammelt (z. B. Organismus und Stamm, experimentelle Bedingungen, Parameter der Datenanalyse). Je nach Art des Experiments ist das sehr umfangreich. Deshalb können die Informationen, die für alle Proben gleich sind, per Makro mit einem Klick in alle relevanten Zeilen übertragen werden, und nur die probenspezifischen Daten werden dann einzeln nachgetragen. Die meisten Einträge werden dabei durch Auswahllisten realisiert, um ein standardisiertes Vokabular zu erhalten. Dabei erfolgt eine Orientierung an der MGED-Ontologie bzw. der PSI-MS-Ontologie um Vergleichbarkeit zu anderen öffentlichen Datenbanken zu gewährleisten. Die tatsächlichen, im Experiment generierten Daten werden im Template nur über ihren Speicherort erfasst; das Template selbst enthält ausschließlich Metadaten.
Datenspeicherung
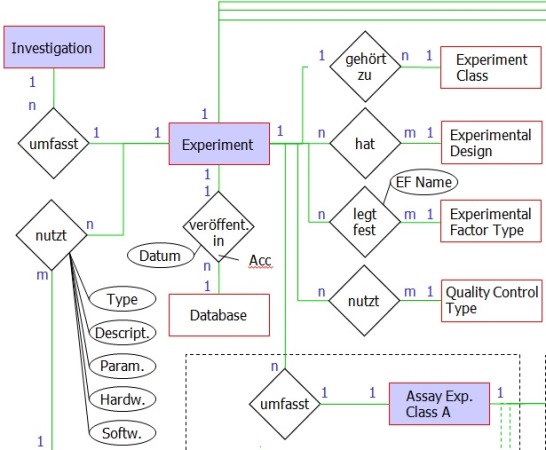
Objektrelationale Datenbanken sind heutzutage Standard für die effektive (d. h. insbesondere speicherplatz- und zugriffszeitsparende) Speicherung großer Datenmengen. Aufgrund positiver Erfahrungen in der Vergangenheit und Eignung für den Anwendungsfall wurde PostgreSQL als Datenbankmanagementsystem ausgewählt. Vor Erstellung der Datenbank muss dabei die Datenstruktur genau bedacht werden, um der Vielfalt der biologischen Daten gerecht zu werden und maximale Erweiterbarkeit zu erhalten (hier ein Ausschnitt des zugehörigen Entity-Relationship-Diagramms). Die hier verwendete Datenstruktur orientiert sich an den Templates, die zur Datenerfassung genutzt werden, und ist optimiert für die Speicherung von Metadaten aus Hochdurchsatz-Experimenten:
Front-end
Für den Zugriff auf die Datenbank bietet sich eine web-basierte Lösung an, da mehrere Institutionen Daten generieren und auf diese von den verschiedenen Standorten aus zugegriffen werden soll. Der Datenbankzugriff selbst wurde dabei mittels PHP realisiert, während die Darstellung als Webinterface in HTML, CSS und JavaScript implementiert wurde. Bei entsprechender Berechtigung kann ein Nutzer sich nun online alle relevanten Metadaten eines Experiments anschauen (der Experimenttitel wurde im Bild entfernt, da die Daten nicht öffentlich zugänglich sind):
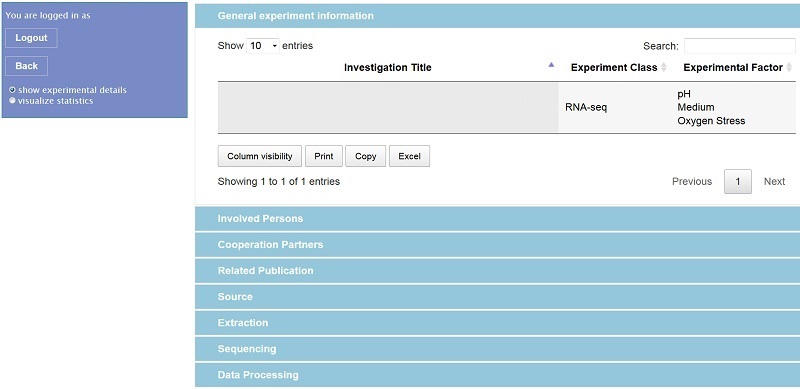
Die dazugehörigen experimentellen Rohdaten sind hierbei (wie auch in den Templates) nur verlinkt, so dass die Experimentatoren kontaktiert werden müssen, um ihre Daten einsehen zu dürfen. Einzelne Ergebnisse (d. h. Gen- bzw. Proteinlisten) der Analysen verschiedener Bedingungen eines Experiments werden aber in der Web-Oberfläche tabellarisch oder geplottet zur Verfügung gestellt:

Mithilfe der Filter- und Visualisierungsparameter können die Tabellen und Plots angepasst werden und so beispielsweise verschiedene Schwellwerte für Foldchanges oder p-Werte getestet oder unterschiedliche experimentelle Bedingungen wie auch Softwareeinstellungen verglichen werden. Die Genlisten sind außerdem verlinkt zu externen Datenbanken. So kann zu jedem Experiment das Maximum an verfügbaren Informationen gesammelt und genutzt werden.
Diese kurze Beschreibung eines aktuellen Anwendungsbeispiels zeigt nur einen Teil der Möglichkeiten, die sich vor allem an den Wünschen der Anwender orientieren (so soll beispielsweise die beschriebene Anwendung im Front-end um eine Upload-Maske sowie Schnittstellen zu externen Tools für Genomvisualisierung und Netzwerkanalyse ergänzt werden).